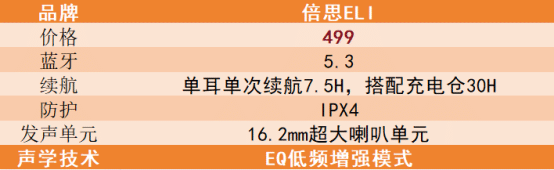
在 .c 文件中,通常不会直接包含编码格式的标注。.c 文件是 C 语言源代码文件,它们通常使用纯文本格式编写,并假定使用某种默认的字符编码。在历史上,ASCII 编码是这些文件的主要编码方式,因为它只包含了基本的英文字符和控制字符,并且与多种字符编码方式(如 ISO-8859-1、Windows-1252 等)兼容,这些编码方式能够表示更多的西欧字符。
然而,随着全球化的发展,支持更多字符集(如中文字符、阿拉伯文字符等)的需求增加,UTF-8 编码逐渐成为了事实上的标准编码方式。UTF-8 编码的一个关键优势是它与 ASCII 编码完全兼容,这意味着只包含 ASCII 字符的 .c 文件在 UTF-8 编码下仍然可以被正确读取。
虽然 .c 文件本身不会直接标注编码格式,但你的开发环境(如文本编辑器、IDE 或构建系统)可能会默认使用某种编码来打开和保存这些文件。在大多数情况下,UTF-8 编码是推荐的,因为它能够表示任何 Unicode 字符,并且与 ASCII 编码兼容。
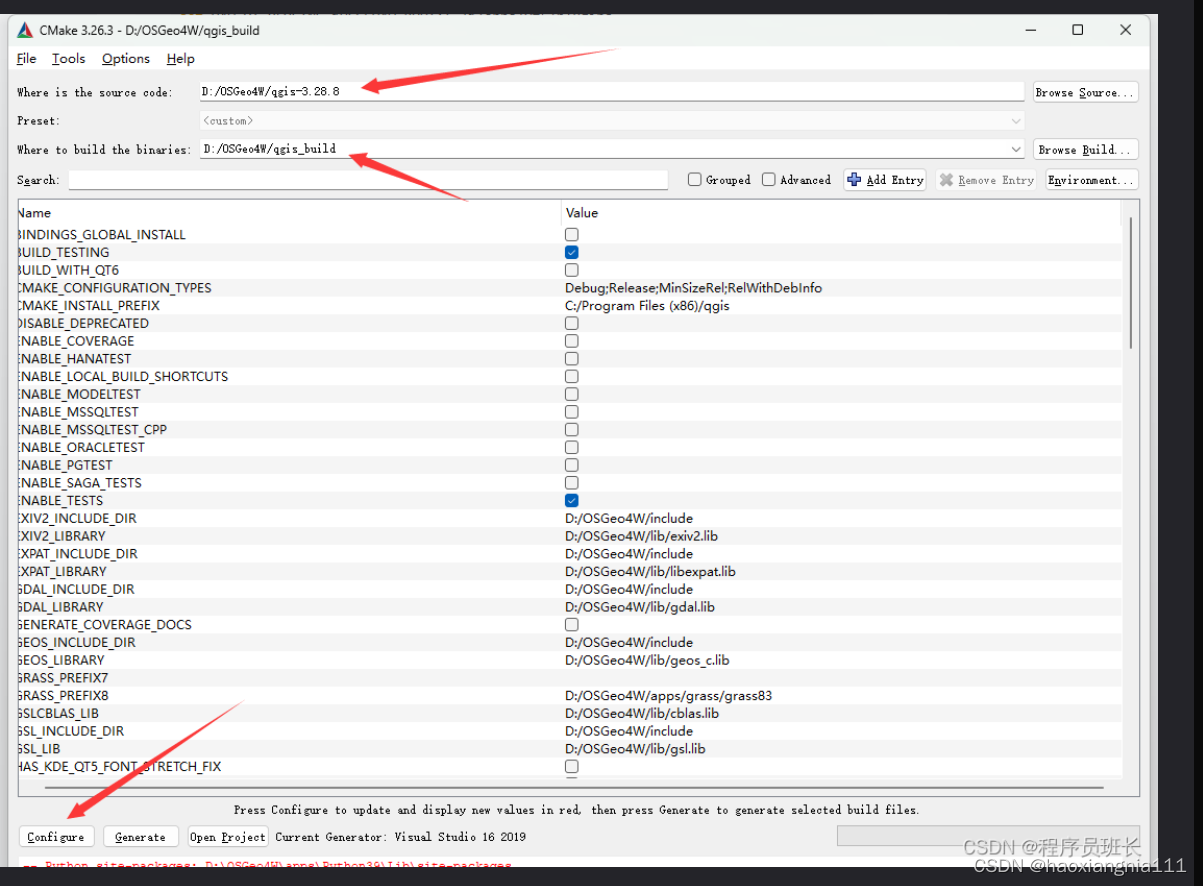
如果你在处理 .c 文件时遇到了编码问题(如乱码),那么可能是因为你的开发环境或构建系统使用了错误的编码来打开或保存文件。你可以通过以下步骤来检查和修复编码问题:
- 检查文本编辑器的编码设置:确保你的文本编辑器或 IDE 默认使用 UTF-8 编码来打开和保存
.c文件。 - 检查构建系统的编码设置:如果你的构建系统(如 Makefile、CMake 等)在处理
.c文件时遇到了编码问题,确保它在读取和写入文件时也使用了正确的编码。 - 使用外部工具检测编码:有些工具(如
file命令在 Linux 系统中)可以检测文件的编码方式。你可以使用这些工具来验证.c文件的编码是否正确。 - 重新保存文件为正确的编码:如果文件的编码不正确,你可以使用文本编辑器将其重新保存为正确的编码(如 UTF-8)。在重新保存之前,请确保备份原始文件以防止数据丢失。